MoE-ACT: Scaling Multi-Task Bimanual Manipulation
with Sparse Language-Conditioned Mixture-of-Experts Transformers
1The Hong Kong University of Science and Technology (Guangzhou), 2The Hong Kong University of Science and Technology
Abstract
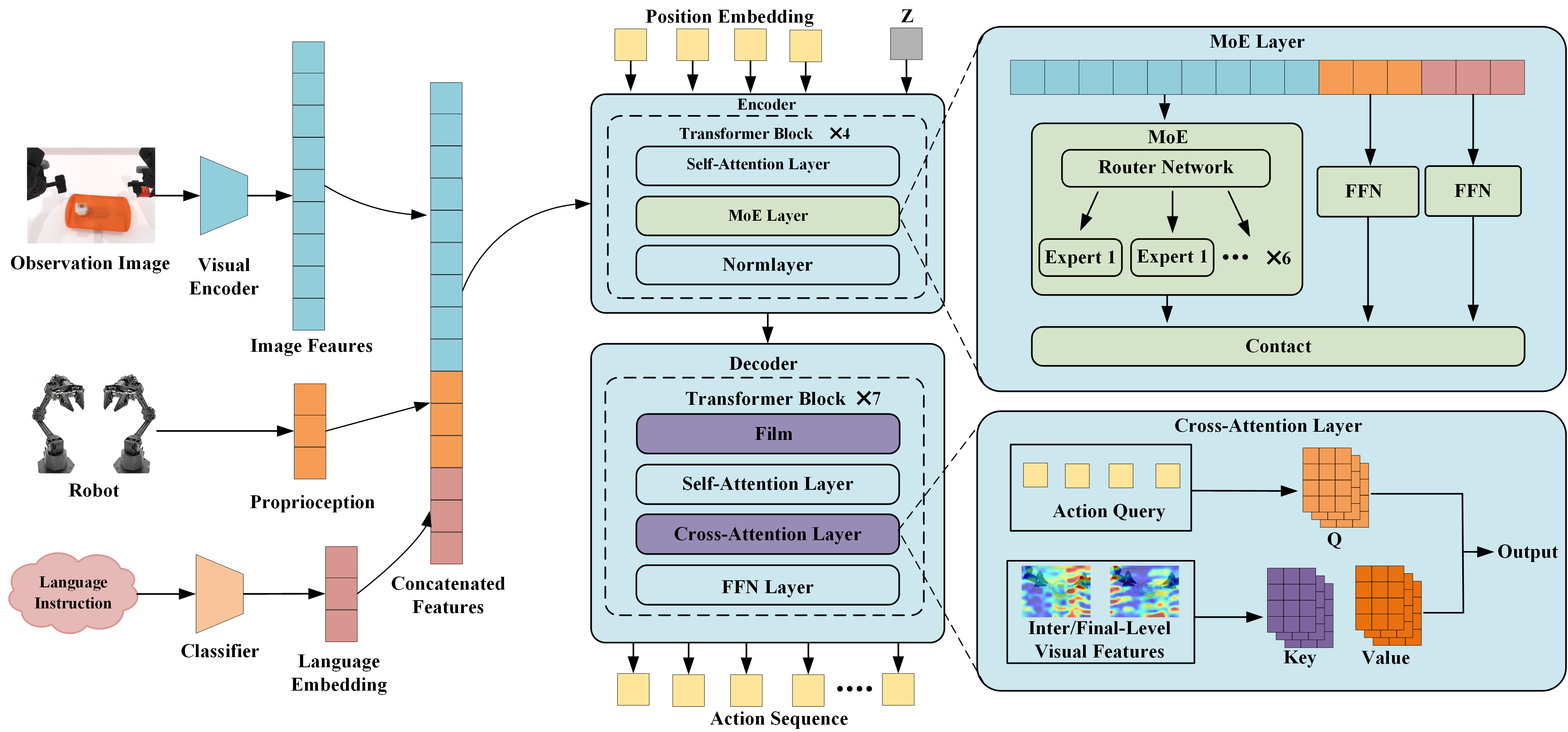
The ability of robots to handle multiple tasks under a unified policy is critical for deploying embodied intelligence in real-world household and industrial applications. However, out-of-distribution variation across tasks often causes severe task interference and negative transfer when training general robotic policies. To address this challenge, we propose a lightweight multi-task imitation learning framework for bimanual manipulation, termed Mixture-of-Experts-Enhanced Action Chunking Transformer (MoE-ACT), which integrates sparse Mixture-of-Experts (MoE) modules into the Transformer encoder of ACT. The MoE layer decomposes a unified task policy into independently invoked expert components. Through adaptive activation, it naturally decouples multi-task action distributions in latent space. During decoding, Feature-wise Linear Modulation (FiLM) dynamically modulates action tokens to improve consistency between action generation and task instructions. In parallel, multi-scale cross-attention enables the policy to simultaneously focus on both low-level and high-level semantic features, providing rich visual information for robotic manipulation. We further incorporate textual information, transitioning the framework from a purely vision-based model to a vision-centric, language-conditioned action generation system. Experimental validation in both simulation and a real-world dual-arm setup shows that MoE-ACT substantially improves multi-task performance. Specifically, MoE-ACT outperforms vanilla ACT by an average of 33% in success rate. These results indicate that MoE-ACT provides stronger robustness and generalization in complex multi-task bimanual manipulation environments.
Simulation Experimental Results
Handover Block
Lift Pot
Experimental Results
Task A: Handover Bottle
Task B: Putting Cubes into a Box
PS: The videos have been accelerated for demonstration purposes.
BibTeX
@misc{guo2026moeactscalingmultitaskbimanual,
title={MoE-ACT: Scaling Multi-Task Bimanual Manipulation with Sparse Language-Conditioned Mixture-of-Experts Transformers},
author={Kangjun Guo and Haichao Liu and Yanji Sun and Ruhan Zhao and Jinni Zhou and Jun Ma},
year={2026},
eprint={2603.15265},
archivePrefix={arXiv},
primaryClass={cs.RO},
url={https://arxiv.org/abs/2603.15265}
}